
What Happened During the AWS Outage of March 2026?
On March 1–2, 2026, Amazon Web Services suffered one of the most severe infrastructure failures in cloud computing history. A catastrophic physical event at AWS data center facilities in the United Arab Emirates (ME-CENTRAL-1 region) triggered structural fires and forced emergency power shutdowns across multiple Availability Zones. The disruption quickly cascaded to the Bahrain region (ME-SOUTH-1) and generated ripple effects felt globally—including service degradation in the Americas, AI platform outages, and the complete shutdown of major SaaS platforms that serve users across Latin America, and the rest of the world.
The global fallout was staggering: 38 AWS services went down in the UAE region, 46 in Bahrain, and a separate Multiple Services Operational Issue was recorded in the critical US-EAST-1 region. Downstream services including Snowflake, Anthropic’s Claude AI, and numerous financial institutions experienced outages that affected millions of users worldwide—including throughout Latin America where AWS-dependent banking, productivity, and AI tools became unavailable for hours.
This article examines the technical anatomy of the AWS outage, its specific consequences for Amazon WorkSpaces and AppStream 2.0 virtual desktop deployments, the global cascading impact on users in the Americas, and provides a comparative analysis of Oracle Cloud Infrastructure (OCI)—which maintained full operational continuity throughout the entire event.
AWS Outage March 2026 Timeline: From Regional Failure to Global Crisis
How the AWS Middle East Data Center Outage Started
At approximately 4:30 AM PST on March 1, 2026, AWS reported that Availability Zone mec1-az2 in the ME-CENTRAL-1 region (UAE) was “impacted by objects that struck the data center, creating sparks and fire.” Local fire departments responded by cutting off all power—including primary feeds and backup generators—to contain the blaze. This was a physically destructive event that rendered critical infrastructure completely inoperable.
Within hours, the AWS outage expanded across the entire Middle East footprint:
- A second Availability Zone (mec1-az3) in the UAE experienced degraded performance due to shared infrastructure dependencies.
- The remaining zone (mec1-az1) reported elevated EC2 API error rates and complete instance launch failures.
- The ME-SOUTH-1 (Bahrain) region began experiencing its own power and connectivity failures, with more than 50 services affected.
- AWS confirmed 38 services fully disrupted in the UAE and 46 services disrupted in Bahrain, including EC2, Lambda, EKS, VPC, RDS, DynamoDB, S3, Redshift, CloudWatch, and CloudFormation.
AWS advised customers that it was not possible to launch new instances in the affected regions and that physical recovery—including structural repair and water damage remediation from fire suppression—could take “a day or more.”
Why a Regional AWS Outage Became a Worldwide Cloud Failure
What made this AWS outage particularly devastating was that it did not stay regional. AWS’s interconnected architecture meant that failures in the Middle East generated cascading effects across the global AWS footprint:
- US-EAST-1 Operational Issue: AWS’s own Health Dashboard recorded a separate Multiple Services Operational Issue in the US-EAST-1 region (Northern Virginia)—the largest and most critical AWS region globally—on both March 1 and March 2, 2026. US-EAST-1 is the backbone for countless global services, and any instability there ripples to every continent.
- Snowflake Data Cloud: Snowflake declared an unresolved incident for its AWS Middle East (UAE) deployment, advising customers that recovery could take “a day or more” and recommending that customers initiate failover procedures immediately.
- Financial Institutions: Reuters reported that financial institutions using AWS services were affected by the outage. Regional banks confirmed their platforms and mobile apps were unavailable due to the region-wide infrastructure disruption.
- Global SaaS Cascade: Any SaaS platform with backend dependencies on the affected AWS regions—or on global services routed through US-EAST-1—experienced degradation or complete failure, impacting businesses on every continent.
Claude AI Goes Down: How the AWS Outage Disrupted Global AI Workflows
One of the most visible casualties of the cascading AWS failure was Anthropic’s Claude AI. Starting at 11:49 UTC on March 2, Claude experienced elevated errors across its entire consumer-facing ecosystem:
- claude.ai, the Claude mobile app, Claude Code, and the developer console all went offline simultaneously.
- Login and logout paths were completely broken—even users with active sessions could not re-authenticate.
- Downdetector logged nearly 2,000 user reports at peak, with 75% affecting chat, 13% mobile app, and 12% Claude Code.
- Bloomberg reported the outage, noting that Anthropic cited “unprecedented demand” compounding the infrastructure strain.
- HTTP 500 and HTTP 529 (overloaded) errors were displayed to users worldwide for hours.
- Multiple models including Claude Haiku 4.5 and Opus 4.6 were affected, with the issue recurring after initial fixes were deployed.
Anthropic’s primary infrastructure runs on AWS through a $4 billion partnership with Amazon. While the core Claude API reportedly remained operational for enterprise customers using direct API integration, every consumer and prosumer interface was down. Claude Code—which now accounts for 4% of all GitHub commits—was inoperative, causing significant delays in development schedules for teams worldwide.
For users in Latin America, the Claude outage was particularly impactful. With Claude increasingly embedded in daily productivity workflows for software development, content creation, data analysis, and business operations, the hours-long blackout left thousands of professionals across the region without access to their primary AI assistant.
AWS Outage Impact in Latin America: Why Distance Doesn’t Equal Protection
The March 2026 AWS outage underscored a critical vulnerability for organizations in the Latin American region. While the physical damage occurred thousands of kilometers away, the global interconnectedness of AWS’s architecture meant the effects were felt as acutely in Buenos Aires as in Dubai:
- US-EAST-1 Dependency Chain: AWS’s SA-EAST-1 region (São Paulo) serves as the primary cloud region for most Latin American deployments. However, many global services that Latin American users depend on—including AI platforms, SaaS tools, and financial services—route through US-EAST-1 for authentication, API management, and control plane operations. When US-EAST-1 experienced its own operational issues on March 1–2, these dependencies broke.
- Proven Pattern: The October 2025 US-EAST-1 outage affected 3,500+ companies across 60+ countries, with AWS Management Console and Support Center suffering increased error rates in South America, Europe, Africa, Asia Pacific, and the Middle East simultaneously. The March 2026 event confirmed this is a systemic architectural vulnerability, not an isolated incident.
- Claude AI and Productivity Tools: The Claude AI outage directly impacted Argentine developers, content teams, and enterprises who rely on Claude for daily workflows. With no regional failover for consumer AI services, users in Buenos Aires experienced the same total blackout as users in New York or Dubai.
- Financial Services Disruption: Banking apps, enterprise SaaS platforms, and fintech services used by Argentine and Brazilian organizations that depend on AWS infrastructure experienced degradation, timeouts, and authentication failures during peak cascading.
- Systemic Regional Risk: The concentration of digital infrastructure dependencies on a single hyperscaler creates compounding risk for the region’s rapidly growing digital economy, where cloud adoption is accelerating across banking, healthcare, government, and education sectors.
As one university IT infrastructure professor noted regarding the cascading nature of cloud failures: when a provider as large as AWS experiences an outage, it doesn’t just stop one service—it can reach thousands of systems that rely on it. For Latin American enterprises, this event was a stark reminder that geographic distance from a data center failure provides no insulation against service disruption in a globally interconnected cloud.
How the AWS Outage Affected Amazon WorkSpaces and AppStream 2.0
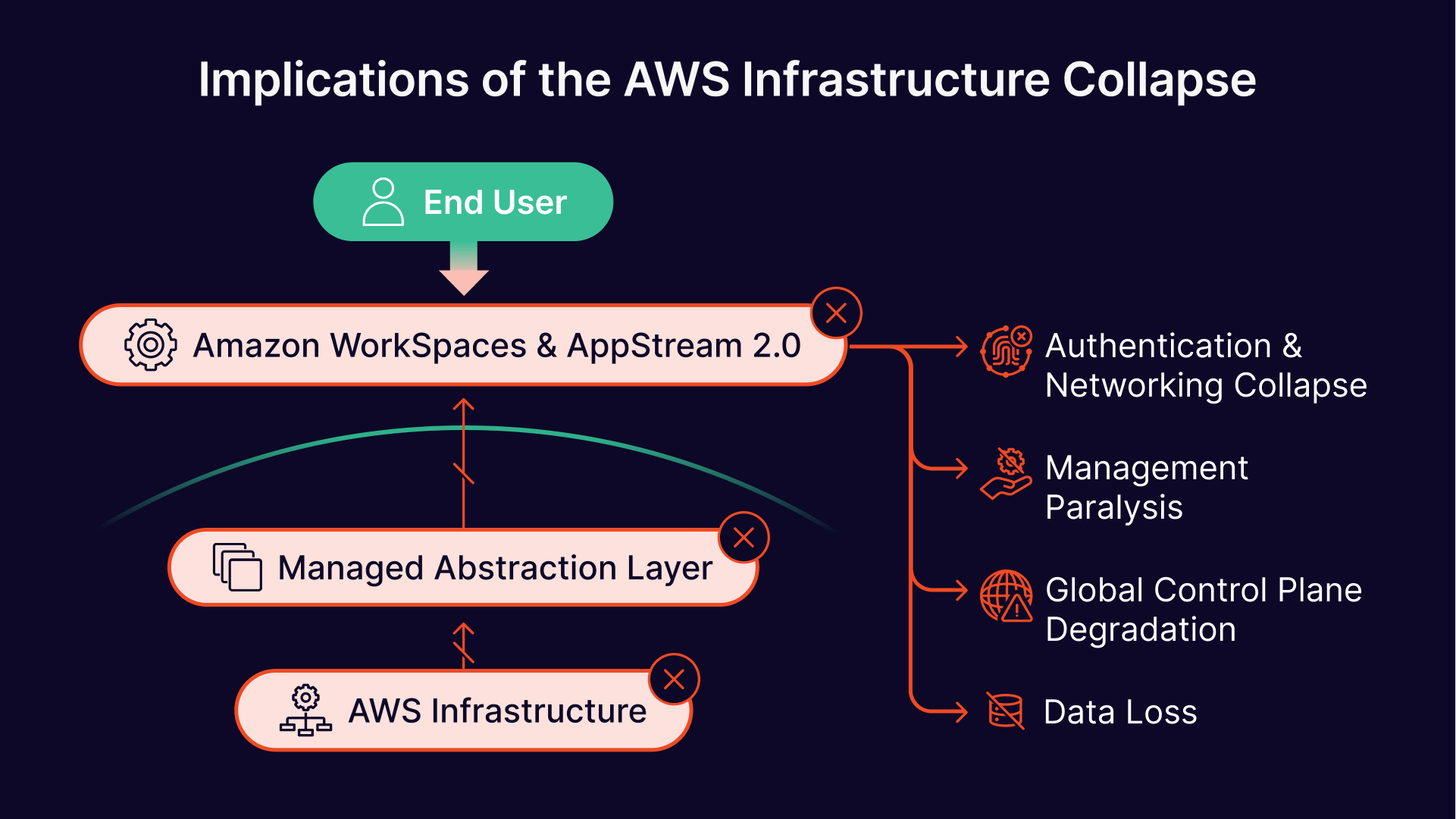
AWS does not publicly disclose the exact number of individual customer deployments affected during an outage. However, the architectural implications for organizations running virtual desktops and application streaming on AWS are unambiguous and severe.
Amazon WorkSpaces and AppStream 2.0: Architectural Dependencies Exposed
Both Amazon WorkSpaces and AppStream 2.0 are marketed as fully managed end-user computing services. However, beneath the managed abstraction layer, they are entirely dependent on foundational AWS infrastructure that proved fragile during this event:
- EC2 and EBS Failures: Every WorkSpaces virtual desktop and every AppStream streaming instance runs on an underlying EC2 compute instance, with user data stored on Elastic Block Store (EBS) volumes. When power was severed to entire Availability Zones, these instances suffered hard, ungraceful shutdowns. EBS volumes in physically damaged facilities face risk of permanent data loss from water damage caused by fire suppression systems.
- Authentication and Networking Collapse: WorkSpaces relies on AWS Directory Service (Microsoft AD Connector or AWS Managed Microsoft AD) for user authentication. AppStream 2.0 depends on IAM, SAML, and networking APIs for session brokering. The outage severely impaired these control-plane services, meaning users could not authenticate, launch sessions, or see their desktops listed in client applications.
- Fleet Management Paralysis: AppStream 2.0’s fleet auto-scaling and image builder services depend on EC2, CloudWatch, and internal service APIs. With these foundations unavailable, fleets could not scale, and image builders could not be launched for recovery or redeployment.
- Global Control Plane Risks: Even WorkSpaces and AppStream deployments in unaffected regions may have experienced degradation if their authentication directories, CloudFormation stacks, or IAM policies had dependencies on the impacted regions or on global services routed through US-EAST-1.
What AWS VDI Users Actually Experienced During the Outage
Organizations that had provisioned their WorkSpaces directories or AppStream fleets exclusively within the downed Availability Zones experienced total, unrecoverable service loss for the duration of the outage. End users encountered:
- Connection timeouts and active session drops without warning.
- Complete inability to access virtual desktops or streamed applications.
- Authentication failures even when attempting to connect from client applications outside the affected region.
AWS advised affected customers to reroute traffic to alternate Availability Zones or entirely different global regions. However, for organizations without a pre-existing multi-region failover architecture—which requires significant advance planning, duplicate infrastructure investment, and ongoing cost—this guidance was effectively useless. There was no infrastructure to fail over to.
This is the fundamental architectural risk of cloud-native VDI: when the managed service goes down, the customer has no independent recovery path. The abstraction that makes Amazon WorkSpaces and AppStream 2.0 easy to deploy also makes them impossible to recover independently.
Oracle Cloud Infrastructure vs. AWS: Side-by-Side Comparison During the March 2026 Outage
The following table summarizes the contrasting outcomes for organizations deployed on AWS versus Oracle Cloud Infrastructure during the March 2026 event:
| Dimension | Amazon Web Services (AWS) | Oracle Cloud Infrastructure (OCI) |
|---|---|---|
| Middle East Regions | ME-CENTRAL-1 (UAE), ME-SOUTH-1 (Bahrain) — Both severely impacted; 84+ services down | Abu Dhabi, Dubai, Jeddah — Zero incidents; all services fully operational |
| Global Cascade | US-EAST-1 Multiple Services Operational Issues on Mar 1–2; downstream services affected worldwide | No cascading effects; OCI Status Dashboard clean across all global regions |
| VDI/EUC Impact | WorkSpaces and AppStream 2.0 fully unavailable in affected zones; global control plane dependencies | OCI Compute and all services fully operational; no VDI workload disruption |
| AI Platform Impact | Claude AI (built on AWS) went down globally for hours affecting millions in LATAM and worldwide | Not applicable — OCI services continued uninterrupted during entire event |
| Recovery Timeline | Multi-day physical repair including structural and water damage; “a day or more” per AWS | No disruption — no recovery needed |
| UAE Architecture | Single region (ME-CENTRAL-1) with 3 AZs; physical event cascaded across 2 of 3 AZs | Dual-region (Abu Dhabi + Dubai) with geographically separated, independent infrastructure |
| LATAM Regions | Single region SA-EAST-1 (São Paulo); no in-country DR option | Dual regions: São Paulo + Vinhedo (Brazil); in-country disaster recovery |
| Sovereign/Dedicated | AWS Outposts — limited service subset; no full cloud-in-customer-DC | OCI Dedicated Region — 150+ services in customer’s own data center |
| Egress Pricing | Higher egress fees; economic disincentive for multi-region DR | 10 TB/month free egress; consistent global pricing encourages distribution |
Why Oracle Cloud Infrastructure Was Not Affected by the AWS Outage
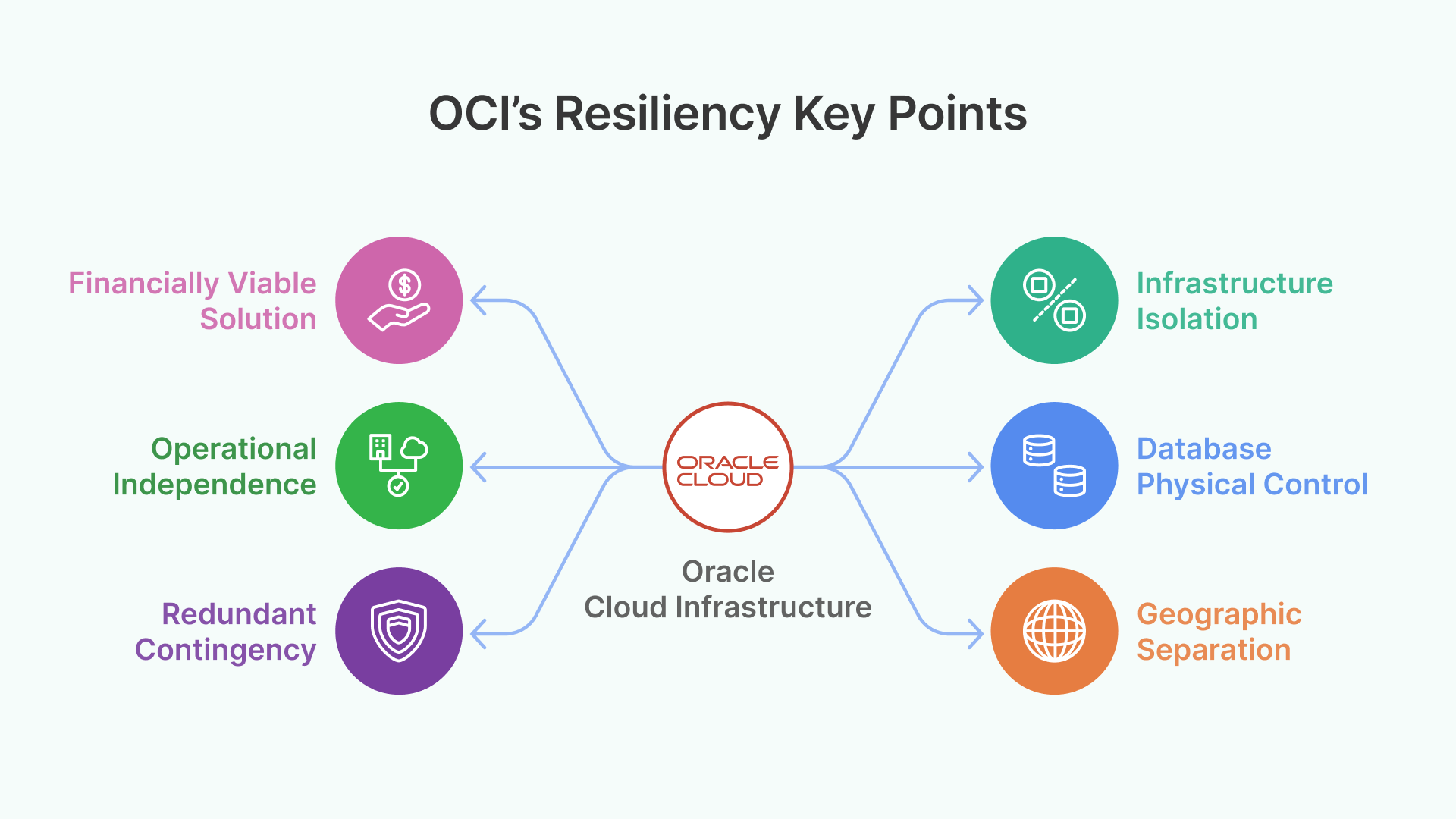
While AWS experienced its most significant outage since October 2025, OCI’s global infrastructure continued to operate with zero incidents. The OCI Status Dashboard reported no disruptions across any service or region during the entire period. StatusGator independently confirmed full operational status as of March 3, 2026, with no user-submitted outage reports and no officially acknowledged outage since October 30, 2025.
Several architectural and strategic factors explain this resilience:
1. Dual-Region Architecture with Geographic Separation
Oracle was the first global hyperscaler to operate two cloud regions in the UAE: Abu Dhabi (me-abudhabi-1) and Dubai (me-dubai-1). These regions are interconnected via a high-speed, low-latency private backbone specifically designed to enable in-country disaster recovery with true geographic and threat-model separation.
Beyond the UAE, OCI operates regions in Jeddah (Saudi Arabia), with additional regions operational or planned in Riyadh, Jerusalem, Johannesburg, NEOM, and Nairobi. Critically for Latin American customers, Oracle operates dual regions in Brazil—São Paulo and Vinhedo—providing in-country redundancy and disaster recovery that AWS’s single SA-EAST-1 region simply cannot match.
2. Fault Domain Architecture and Infrastructure Isolation
OCI regions are designed with Availability Domains (ADs) and Fault Domains (FDs) that provide layered resilience. Availability Domains are isolated data centers with completely independent power, cooling, and network infrastructure. Each AD contains three Fault Domains providing hardware-level anti-affinity, and software deployments are staggered across FDs to prevent single points of failure.
This multi-layered approach—ADs for facility-level isolation and FDs for hardware fault tolerance—creates a defense-in-depth model inherently more resistant to the cascading failures that defined the AWS outage.
3. OCI Dedicated Region: Complete Sovereign Cloud in Your Data Center
The most strategically significant differentiator is OCI Dedicated Region. Unlike AWS Outposts (which offers a limited subset of services), OCI Dedicated Region provides more than 150 of the same cloud services available in Oracle’s public cloud regions—deployed entirely within a customer’s own data center. Both the data plane and control plane remain on-premises, providing complete data sovereignty and physical control.
Organizations can start with as few as 3 racks and scale to more than 450 racks. Oracle installs, operates, supports, and upgrades each Dedicated Region exactly as it maintains public cloud regions worldwide, with identical SLAs for availability, manageability, and performance.
For organizations in Latin America, this capability is transformative. A bank, airline, government agency, or healthcare provider can deploy a complete, Oracle-managed cloud region inside their own secure facility—retaining physical control over infrastructure while benefiting from cloud economics, automation, and the full breadth of OCI services. An external infrastructure event at any public cloud data center anywhere in the world would have zero impact on their operations.
4. Consistent Global Pricing That Makes Multi-Region DR Viable
OCI offers identical pricing in every region worldwide—including dedicated and government regions—with 10 TB per month of outbound bandwidth at no cost. This pricing consistency removes the economic barriers that often discourage multi-region deployment. In contrast, AWS’s higher and variable egress fees create a financial disincentive for customers to distribute workloads across regions, leading to the exact concentration risk that this outage exposed.
For Latin American enterprises, OCI’s dual Brazilian regions (São Paulo and Vinhedo) combined with consistent pricing make true in-country disaster recovery architectures both technically and economically viable—a critical advantage for industries subject to data sovereignty requirements.
5. True Regional Independence Without Hidden Global Dependencies
A critical lesson from this AWS outage is that AWS’s regions are not as independently isolated as their marketing suggests. A physical event in the Middle East generated operational issues in US-EAST-1, cascading failures for global SaaS providers, and a worldwide outage for services like Claude AI.
OCI’s architecture uses a private, redundant, Oracle-managed backbone to interconnect regions while maintaining true operational independence. Each region operates with its own control plane, and failures in one region are architecturally prevented from propagating to others. This is the fundamental difference: OCI’s regions are designed to be truly independent, not just geographically separated.
Thinfinity VDI on Oracle Cloud: Building Resilient Virtual Desktops That Survive Cloud Outages
The AWS outage validates a core architectural principle that Thinfinity’s VDI solutions are built around: resilience through distribution, sovereignty through control, and independence from any single cloud provider.
Unlike Amazon WorkSpaces and AppStream 2.0—which lock customers into AWS-specific infrastructure and create irrecoverable single-provider dependencies—Thinfinity’s platform-agnostic architecture can be deployed on any cloud, on-premises infrastructure, or hybrid combination. When deployed on OCI, Thinfinity customers benefit from:
- Multi-region failover across OCI’s dual UAE regions (Dubai + Abu Dhabi), dual Brazilian regions (São Paulo + Vinhedo), and the broader global footprint of 50+ regions across 28 countries.
- Dedicated Region deployments for sovereign, on-premises cloud environments that are completely immune to external infrastructure events at public cloud facilities.
- Zero Trust Network Access (ZTNA) architecture that reduces dependency on any single cloud provider’s networking stack, authentication services, or control plane.
- Oracle Cloud Marketplace distribution enabling rapid, standardized deployment across any OCI region worldwide.
- Consistent pricing that makes multi-region DR architectures economically rational—not a luxury reserved for only the largest enterprises.
For Thinfinity customers in Latin America specifically, OCI’s dual Brazilian regions provide low-latency, in-region deployment with built-in disaster recovery—something that AWS’s single SA-EAST-1 region cannot match without cross-region failover to US-EAST-1, which this outage proved is itself vulnerable to cascading failures.
1. Never Deploy VDI in a Single Availability Zone or Region. Multi-region architectures are a necessity for business continuity. Both WorkSpaces directories and AppStream fleets must be replicated across geographically separated regions. This outage proved that even multiple AZs within a single region can fail simultaneously when the root cause is physical.
2. Question Single-Provider Dependencies Rigorously. The Claude AI outage demonstrated that when your entire stack runs on one provider (AWS), their failures become your failures—globally and without recourse. Organizations should evaluate platform-agnostic solutions like Thinfinity that can run on any cloud or on-premises environment.
3. Evaluate Sovereign and Dedicated Cloud Options. For organizations in geopolitically sensitive or rapidly growing regions like Latin America and the Middle East, OCI Dedicated Region offers a fundamentally different risk profile than public cloud-only deployments. Physical control over infrastructure is the ultimate protection against external events.
4. Budget for Multi-Region DR from Day One. OCI’s consistent global pricing, low egress costs, and dual-region offerings in key markets (UAE, Brazil, and others) make multi-region DR architectures economically viable. AWS’s higher egress fees and variable regional pricing often discourage the geographic distribution that could have prevented this exact scenario.
5. Recognize That “Managed” Does Not Mean “Resilient.” Amazon WorkSpaces and AppStream 2.0 abstract away infrastructure complexity, but they also abstract away the customer’s ability to independently recover. When the managed service fails, there is no fallback. True resilience requires architectural independence from the VDI layer.
6. Audit Your Complete AI and SaaS Dependency Chain. This outage revealed that critical tools like Claude AI, Snowflake, and countless SaaS platforms share AWS infrastructure dependencies. Organizations should map their full dependency chain and ensure that no single cloud provider failure can simultaneously take down their VDI, AI tools, data platforms, and business applications.
Conclusion: The AWS Outage of March 2026 Changes the Cloud VDI Conversation
The March 2026 AWS outage represents a watershed moment for the cloud industry and for every organization that depends on virtual desktop infrastructure. With 84+ services disrupted across two Middle Eastern regions, cascading operational issues in US-EAST-1, global SaaS platforms like Snowflake taken offline, and AI platforms like Claude made unavailable to millions of users from Buenos Aires to Dubai—this was not a regional event. It was a global infrastructure crisis that exposed the systemic fragility of over-reliance on a single cloud provider.
For organizations evaluating virtual desktop infrastructure strategies, this event underscores the critical importance of geographic distribution, platform independence, and sovereign cloud capabilities. Oracle Cloud Infrastructure’s uninterrupted operation during this crisis—enabled by its dual-region architecture, fault-domain isolation design, Dedicated Region on-premises offering, and consistent global pricing—demonstrates a fundamentally more resilient approach to cloud infrastructure.
Thinfinity’s VDI platform, deployed on OCI, offers enterprises the architectural flexibility to build resilient, sovereign, multi-region virtual desktop environments designed to survive not just software failures, but the increasingly unpredictable physical and systemic threats that characterize today’s global infrastructure landscape.
For customers in Argentina, Latin America, the Middle East, and worldwide, the lesson from the AWS outage of March 2026 is clear: true VDI resilience requires both the right platform and the right architecture.
Appendix: AWS Outage History – A Pattern of Escalating Failures
The March 2026 AWS outage is not an isolated incident. AWS has experienced an accelerating pattern of significant outages that expose systemic architectural risks:
| Date | Region | Root Cause | Global Impact |
|---|---|---|---|
| Feb 10, 2026 | US-EAST-1 | CloudFront DNS failures | Cascaded to 20+ services globally |
| Feb 2026 | US-EAST-1 | Lambda outage | Global issues across multiple services |
| Oct 28, 2025 | US-EAST-1 | EC2/ECS launch delays | Container orchestration failures |
| Oct 20, 2025 | US-EAST-1 | DNS resolution failure | 3,500+ companies, 60+ countries, 15 hours |
| Mar 1–2, 2026 | ME-CENTRAL-1, ME-SOUTH-1, US-EAST-1 | Physical destruction + global cascade | 84+ services, Claude AI, Snowflake, multi-day recovery |
By contrast, OCI’s last acknowledged outage was on October 30, 2025, and the platform reported zero incidents across all regions throughout the entire March 2026 event.