TL;DR
- Cloud VDI is metered per hour, but users work ~45 hours a week — leaving 70%+ of compute idle. A 1,000-seat always-on deployment wastes 770,000 host-hours annually; at 5,000 seats, that’s $400K–$600K/year in compute alone.
- Thinfinity Cloud Manager’s auto-scaling engine closes the gap with three building blocks: Scale Sets (Initial / Lazy / Max capacity tiers), Deploy/Destroy modes (On Demand, Scheduled, or Both), and three VDI deployment models (session-based, 1-to-1, dedicated).
- Graceful Drain marks hosts as draining, lets active sessions finish, then powers off — so scheduled scale-downs never disconnect users mid-task.
- Every Scale Set is defined in Terraform (main.tf, providers.tf, schema.json, uischema.json). Every change is a Git commit — SOX-friendly audit trail by design.
- The same scaling logic runs on OCI, AWS, Azure, GCP, and IONOS — enabling multi-region, multi-cloud failover, and cloud arbitrage that Citrix DaaS, Omnissa Horizon, and Azure AVD can’t deliver in a single control plane.
The Cloud VDI Cost Problem Nobody Talks About
Your VDI infrastructure runs 168 hours a week. Your users work 45. In an on-premises data center, that idle capacity was a sunk cost buried in depreciation schedules. In the cloud, it’s a metered expense. Every hour a VM runs without serving a user session is a direct line item on your cloud invoice.
This is the fundamental problem with cloud VDI: the pricing model exposes waste that was previously invisible. OCI charges $0.03/core-hour for E4.Flex instances. AWS charges $0.0416/vCPU-hour for m5.xlarge. Azure charges $0.192/hour for D4s_v3. These rates are per-hour, per-instance, regardless of whether a user is connected.
A 1,000-seat VDI deployment sized for peak concurrency requires approximately 125 hosts (at 8 sessions per host). Running those 125 hosts 24/7/365 means paying for 1,095,000 host-hours per year. Actual demand—office hours, Monday through Friday—consumes roughly 325,000 host-hours. The remaining 770,000 host-hours are waste. At OCI E4.Flex rates ($0.12/host-hour for a 4-core instance), that’s $92,400 per year in idle compute for a single 1,000-seat deployment.
Scale that to 5,000 seats across multiple regions and you’re looking at $400,000–$600,000 annually in compute charges for VMs that serve no users. Add Windows Server licensing, RDS CALs, storage I/O, and network egress, and the total waste exceeds $1M. This isn’t a hypothetical: the Flexera 2026 State of the Cloud Report documents that wasted cloud spend ticked up to 29% in 2026 — the first uptick in five years, driven largely by always-on workloads that nobody powers down.
![]()
Despite the increase in FinOps maturity placing focus on value, this year’s report shows cloud-based AI workloads are surging causing an increase in wasted cloud spend (29%) for the first time in five years.
| Metric | 1,000 Seats | 5,000 Seats |
|---|---|---|
| Peak Hosts Required | 125 | 625 |
| Hours/Year (24/7) | 1,095,000 | 5,475,000 |
| Actual Demand Hours | 325,000 | 1,625,000 |
| Wasted Host-Hours | 770,000 | 3,850,000 |
| Wasted Compute Cost (OCI) | $92,400 | $462,000 |
| Wasted Licensing + Storage | $180,000+ | $900,000+ |
The question isn’t whether you can afford auto-scaling. It’s whether you can afford not to have it.
What Citrix and Omnissa Actually Offer — And Where They Fall Short
Both Citrix and Omnissa (formerly VMware Horizon, spun off from Broadcom in 2024) have auto-scaling capabilities. This section describes what they actually do, based on current documentation, and where the gaps are for multi-cloud enterprise deployments.
Citrix DaaS Autoscale: Capable but Cloud-Locked
Citrix Autoscale is a genuine auto-scaling feature. It supports both schedule-based and load-based scaling, works with multi-session and single-session delivery groups, and provides 30-minute scheduling granularity for multi-session pools. Citrix brought Autoscale to on-premises deployments in August 2023, extending what was previously a DaaS-only feature to Citrix Virtual Apps and Desktops 7.
![]()
Autoscale allows admins to vary the powered-on capacity with 30 min granularity and allows for different schedules on different days. If a volatile workload is expected, it is advised to configure the capacity buffer to avoid users having to wait for machines to power on.
What Citrix Autoscale does well:
- Schedule-based power management: Define peak and off-peak hours with 30-minute granularity. Set the number of powered-on machines per time slot. Different schedules for different days of the week.
- Load-based scaling: Dynamically power on additional machines as session load increases. Capacity buffer ensures new users don’t wait for cold boots.
- Drain mode: Isolate low-utilization VMs, stop assigning new sessions, and allow existing sessions to complete before powering off.
- Tagged machine scaling: Apply Autoscale only to a subset of machines using tags—useful for cloud-bursting scenarios where on-premises machines handle baseline load and cloud instances handle overflow.
- Dynamic provisioning: Create and delete machines via Machine Creation Services (MCS), including disk deallocation when machines aren’t needed.
Where Citrix falls short for multi-cloud enterprises:
- Single control plane: Citrix DaaS runs on Citrix Cloud. Your scaling policies, delivery groups, and machine catalogs live in Citrix’s cloud tenancy. Multi-cloud failover (e.g., overflow from OCI to AWS) requires multiple resource locations configured within a single Citrix tenant, with zone preference rules. It works, but routing logic is Citrix-managed, not yours.
- Licensing cost at scale: Citrix DaaS subscription pricing runs $20–$40/user/month depending on tier (DaaS Standard vs. Premium). A 5,000-seat deployment at $30/user/month = $1.8M/year in Citrix licensing alone—before cloud compute costs. This is the fee for the control plane and brokering, not the VMs themselves.
- No Terraform-native IaC: Citrix scaling policies are configured through Citrix Studio or Citrix Cloud console. There’s a Citrix PowerShell SDK and REST APIs, but no native Terraform provider for Autoscale configuration. Compliance teams that require Git-versioned, auditable infrastructure-as-code must build custom wrappers.
- Single-session static limitations: Autoscale for single-session static (persistent) desktops doesn’t support schedule-based scaling—only power management of assigned machines. Users who need persistent desktops lose schedule-based cost optimization.
Omnissa Horizon: Multi-Hypervisor Expansion, Limited Cloud Scaling
Omnissa Horizon (the VMware Horizon product line, now independent from Broadcom after the 2024 spin-off) has expanded hypervisor support beyond vSphere. The Horizon 8 2512 release added GA support for Nutanix AHV, and Omnissa ONE 2025 announced integration with Platform9 Private Cloud Director. This is meaningful—Horizon is no longer a VMware-only product.
However, Horizon’s auto-scaling capabilities remain limited compared to cloud-native solutions:
- Pool sizing, not dynamic scaling: Horizon uses instant-clone pools with defined minimum and maximum sizes. The pool maintains a ‘spare’ count of available desktops. When the spare count drops below threshold, new clones are provisioned. This is reactive provisioning, not proactive scheduling.
- No schedule-based pre-warming: Horizon cannot pre-warm hosts 15 minutes before a shift starts. You define a static pool size with spare counts. Users arriving at shift start may trigger clone provisioning, adding 30–90 seconds of boot time before session availability.
- Licensing upheaval: Post-Broadcom, VMware/Omnissa licensing shifted entirely to subscription. Perpetual licenses are discontinued. Industry reports document 200–500% price increases for customers transitioning to the new model, with some cases exceeding 1,000%. The minimum core requirement per CPU increased from 16 to 72 starting April 2025, impacting smaller deployments disproportionately.
- vSphere-centric architecture: Despite Nutanix and Platform9 support, Horizon’s scaling logic is tied to on-premises or hybrid infrastructure. True multi-cloud scaling (spin up overflow capacity on OCI when Azure is saturated) requires manual orchestration or third-party tooling.
- No infrastructure-as-code: Horizon pool configuration is GUI-driven or API-driven (REST). No native Terraform provider for pool scaling policies. No Git-versioned audit trail for scaling configuration changes.
Azure Virtual Desktop: Azure-Only
Azure Virtual Desktop (AVD) has native scaling plans that support schedule-based and load-based scaling. It works well within Azure. The limitation is exactly what you’d expect: it’s Azure-only. Multi-cloud deployments, OCI-primary architectures, or hybrid OCI/AWS strategies cannot use AVD scaling. Organizations running VDI across multiple clouds need a cloud-agnostic scaling engine.
How Thinfinity Cloud Manager’s Auto-Scaling Engine Works
Thinfinity Cloud Manager’s auto-scaling operates on three pillars: Scale Sets (capacity-defined pools), Deploy/Destroy modes (on/off scheduling), and VDI Deployment Models (session-based, 1-to-1, dedicated). Each addresses a different dimension of cloud VDI cost optimization.
Scale Sets: The Core Capacity Unit
A Scale Set is a pool of identical cloud instances running the same OS image and application stack. Every Scale Set is defined by three capacity parameters that control how the pool grows and shrinks:
- Initial Instances: The baseline number of hosts that run continuously. These are your always-on capacity—the floor below which the pool never drops. For a standard office-hours workload, this might be 10–20% of peak capacity: enough to handle early arrivals and unpredictable demand.
- Lazy Instances: The on-demand buffer. These hosts exist as configurations but don’t consume compute until triggered. When session demand approaches Initial Instance capacity, Lazy Instances spin up automatically. They’re the elastic layer between your baseline and your ceiling.
- Max Instances: The hard ceiling. The pool will never exceed this count regardless of demand. This prevents runaway scaling—a misconfigured threshold or session leak can’t spin up 500 hosts and blow your cloud budget. Max Instances is your financial safety valve.

Example: A contact center with 500 agents during peak hours might configure Initial Instances = 15 (covers 120 sessions at 8 per host), Lazy Instances = 50 (covers overflow to 520 sessions), and Max Instances = 65 (hard cap at 520 sessions). Outside business hours, only the 15 Initial Instances run. During peak, the pool scales to whatever demand requires, up to 65 hosts.
Deploy Modes: When and How Instances Come Online
The Deploy section controls when instances are created and powered on. Cloud Manager offers three deploy modes:
- On Demand: Instances spin up only when session load triggers scaling thresholds. No pre-warming, no schedules. Pure reactive scaling. Best for unpredictable workloads like support queues or incident response teams.
- Scheduled: Instances are pre-provisioned according to a weekly schedule grid. You define which days of the week (Monday through Sunday) and what time window (From/To) instances should be active. For example: Monday–Friday, 9:00 AM to 7:00 PM. Outside that window, Lazy Instances power down automatically. This is the most cost-effective mode for predictable business-hours workloads.
- Both: Combines Scheduled and On Demand. The schedule handles predictable capacity (pre-warm at 8:45 AM, scale down at 7:00 PM), while On Demand handles unexpected spikes within the scheduled window. This is the recommended mode for most enterprise deployments.
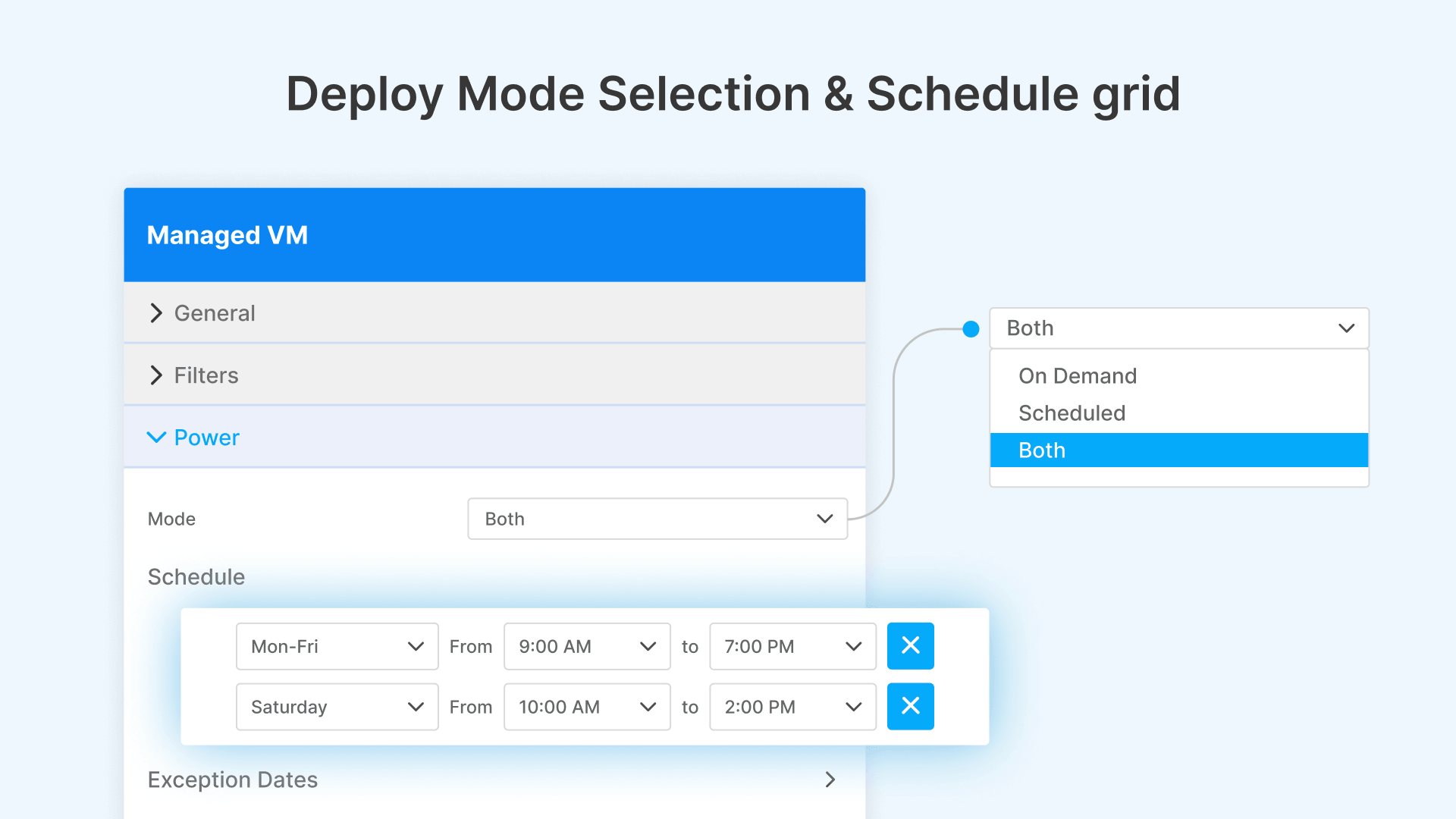
The schedule grid is granular. Each day of the week has its own From/To time range. You can configure Monday–Friday for standard business hours (9:00 AM–7:00 PM), Saturday for reduced hours (10:00 AM–2:00 PM), and Sunday off entirely. Or run 24/7 on weekdays with reduced weekend coverage. The schedule adapts to your operational calendar.
Pre-warming happens automatically before the scheduled start time. If your schedule says 9:00 AM, Cloud Manager begins provisioning instances at approximately 8:45 AM, so hosts are booted, domain-joined, and ready to accept sessions by the time users arrive. No cold-boot delays.
Destroy Modes: Controlling When Instances Power Off
The Destroy section controls what happens to instances when they’re no longer needed. Two modes:
- Never: Instances are never automatically destroyed. Once provisioned, they remain available until manually removed. Use this for persistent desktops, compliance environments where VMs must retain state, or scenarios where boot time is prohibitive.
- Scheduled: Instances are automatically powered off and deallocated according to the destroy schedule. When the scheduled window ends, Cloud Manager initiates the Graceful Drain Procedure (described below), waits for active sessions to complete, and then powers off the host. The VM and its associated compute/storage charges stop accruing.
The combination of Deploy: Scheduled and Destroy: Scheduled is where the major cost savings occur. You’re paying for cloud compute only during the hours your users actually work. A Monday–Friday 9:00 AM–7:00 PM schedule means you’re paying for 50 hours of peak compute per week instead of 168. That’s a 70% reduction in Lazy Instance compute charges.
Graceful Drain: Zero-Disruption Scale-Down
When scale-down fires—whether triggered by schedule, threshold, or manual action—Cloud Manager does not forcibly terminate sessions. Instead, it initiates the Graceful Drain Procedure:
- The target host is marked ‘draining.’ The connection broker stops assigning new sessions to this host.
- Existing sessions continue uninterrupted. Users working on draining hosts notice nothing.
- Cloud Manager monitors the draining host’s active session count in real-time.
- When the last session disconnects, the host powers off immediately. Compute charges stop.
- If sessions persist beyond the configurable grace period, Cloud Manager sends a notification to the user and, after the timeout, forces disconnection. This prevents hosts from running indefinitely due to idle or abandoned sessions.
This is the mechanism that makes scheduled scaling safe for production. Users are never mid-sentence when their VM disappears. The drain procedure ensures continuity.
VDI Deployment Modes: Session-Based, 1-to-1, and Dedicated
Cloud Manager’s auto-scaling engine isn’t a one-size-fits-all mechanism. It adapts to three distinct VDI deployment models, each with different scaling behaviors and cost profiles.
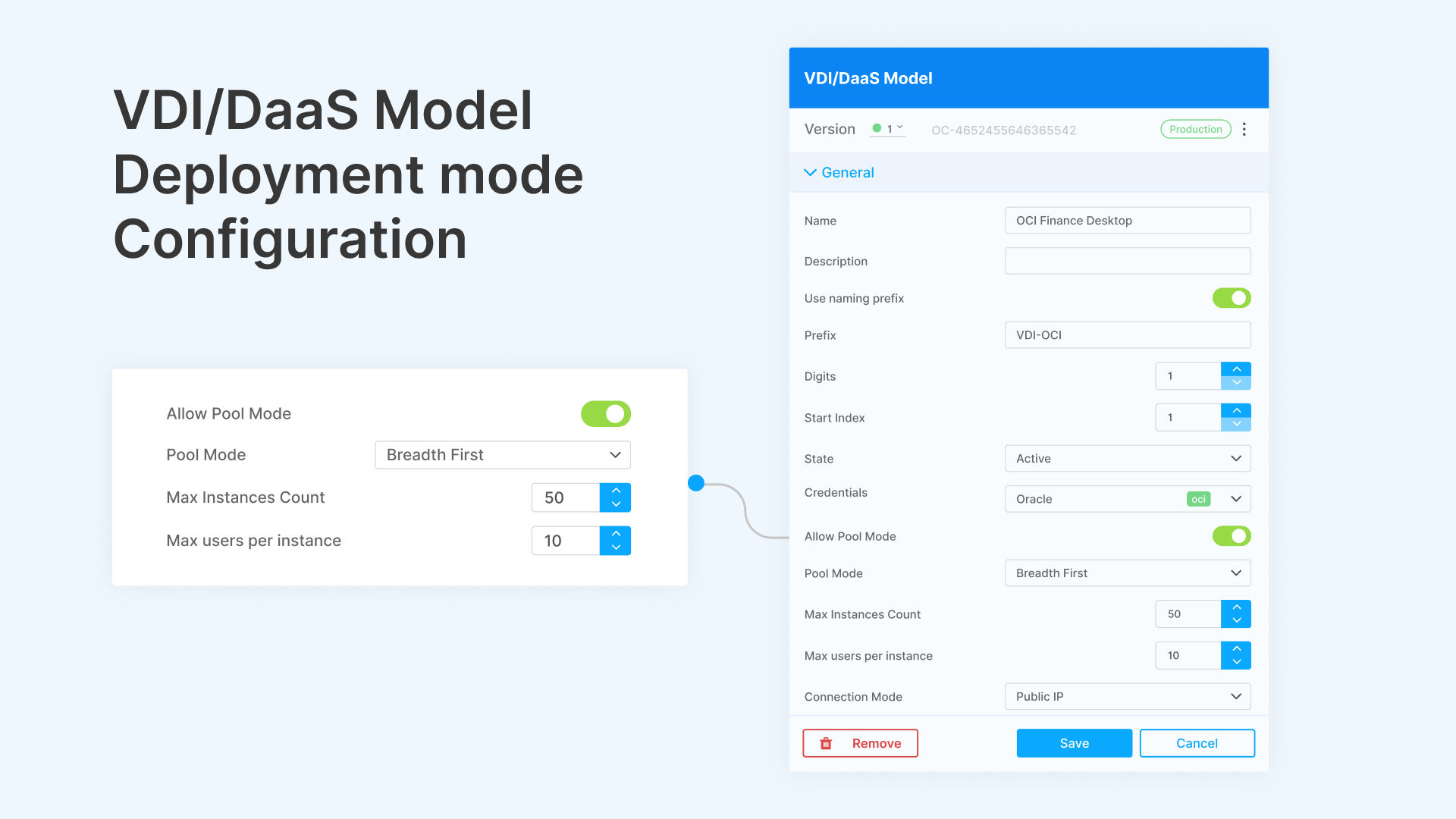
Session-Based Scaling: Multiple Users Per Host
In session-based mode, each host serves multiple concurrent user sessions. You define how many users a single host can support (sessions per host), and Cloud Manager scales the host count based on that density ratio and a demand threshold.
Configuration parameters:
- Sessions per host: The maximum number of concurrent sessions a single host can serve. Typical values: 8–15 for knowledge workers (Office, browser, email), 4–6 for power users (CAD, development environments), 2–3 for GPU-accelerated workloads (3D rendering, video editing).
- Scaling threshold: The percentage of current capacity at which new hosts spin up. Example: if sessions per host = 10 and threshold = 75%, a host pool of 5 (capacity = 50 sessions) triggers scaling when session count hits 38 (75% of 50).
- Pool Mode: Enables pooled desktop assignment. Users connect to any available host in the pool. Sessions are non-persistent—when the user disconnects, the session state is discarded (or saved to a profile management layer like FSLogix). This mode delivers the highest density and lowest cost per user.
- Dynamic Assignment: When enabled, users are dynamically assigned to the least-loaded host at connection time. Combined with Pool Mode, this ensures even distribution across hosts and prevents hotspots.

Session-based scaling is the default for contact centers, call centers, and shift-work environments. A 500-agent contact center with 10 sessions per host needs 50 hosts at peak. With scheduled scaling (9 AM–7 PM), only the 15 Initial Instances run outside business hours. During peak, Lazy Instances bring the pool to 50. Cost savings: 70% of off-peak compute eliminated.
1-to-1 Scaling: One User, One VM
In 1-to-1 mode, each user gets a dedicated VM for the duration of their session. The VM is created on demand (or pre-warmed by schedule), assigned to the user at login, and returned to the pool (or destroyed) at logout. This provides full isolation between users—no shared host resources, no noisy-neighbor performance degradation.
1-to-1 mode is appropriate for:
- Regulated industries: HIPAA, PCI-DSS, and GLBA environments where session isolation is a compliance requirement. Each user’s VM is a separate security boundary with its own audit trail.
- Developer workstations: Developers running builds, containers, or local databases need dedicated CPU and memory. Session-based density would create contention.
- GPU workloads: CAD, 3D rendering, and video editing users need dedicated GPU passthrough. GPU sharing (vGPU) isn’t always sufficient for professional workflows.
Auto-scaling in 1-to-1 mode works differently. Instead of scaling hosts based on sessions-per-host density, Cloud Manager maintains a pool of pre-provisioned VMs (the ‘warm pool’). When a user logs in, a VM is assigned from the warm pool. When the warm pool drops below a threshold, new VMs are provisioned. When VMs are released (user logout), they’re either reset and returned to the warm pool or destroyed (depending on Destroy mode).
The naming prefix in Cloud Manager controls VM naming conventions. You define a prefix (e.g., ‘CC-‘ for call center), a digit count, and a start index. VMs are named CC-001, CC-002, CC-003, and so on. This makes operational tracking straightforward in cloud consoles and monitoring tools.
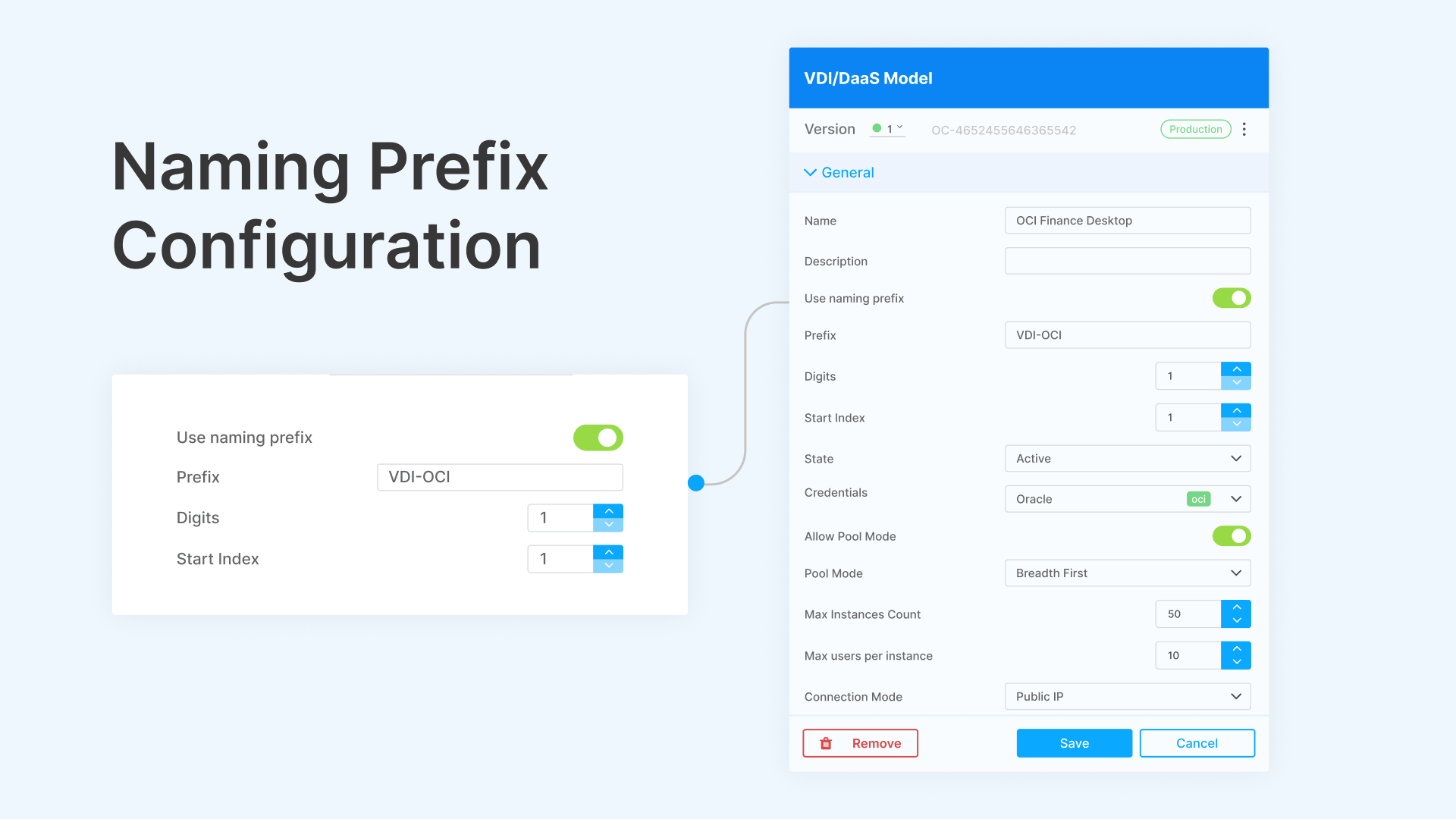
Dedicated Machines: Persistent VMs with On/Off Control
Dedicated mode assigns a specific VM to a specific user permanently. The user always connects to the same machine—their files, settings, installed applications, and desktop state persist across sessions. This is traditional persistent VDI.
What makes Cloud Manager’s dedicated mode different from legacy persistent VDI is the on/off scheduling. In traditional deployments (Citrix, Horizon), persistent desktops run 24/7 because there’s no automated mechanism to power them off safely and power them back on before the user’s next session. Cloud Manager solves this:
- Scheduled power-on: The user’s VM boots automatically before their work schedule. If Maria in accounting works 8 AM–5 PM, her dedicated VM powers on at 7:45 AM. By 8:00 AM, it’s at the Windows desktop, ready for RDP.
- Scheduled power-off: At 5:00 PM (or after Maria disconnects, whichever comes later), the VM powers off. Compute charges stop. Storage persists (the disk stays allocated), but CPU and memory billing ends.
- Manual override: Users can power on their dedicated VM outside the schedule via the Thinfinity portal. For late-night work or weekend access, the user clicks ‘Start My Desktop’ and the VM boots on demand. It powers off automatically after the next scheduled destroy window or after a configurable idle timeout.
For a 1,000-user dedicated VDI deployment where users work standard business hours (50 hours/week), scheduled on/off reduces compute from 168 hours/week to 50 hours/week per VM. That’s a 70% reduction in per-user compute cost—without changing the user experience. Users still get their personal, persistent desktop. It just doesn’t run when nobody’s using it.
Cloud Infrastructure Parameters: What Gets Provisioned
When Cloud Manager provisions a new instance (whether by schedule or on demand), it needs to know what to build. The Parameters section defines the cloud infrastructure specification for every instance in the Scale Set.
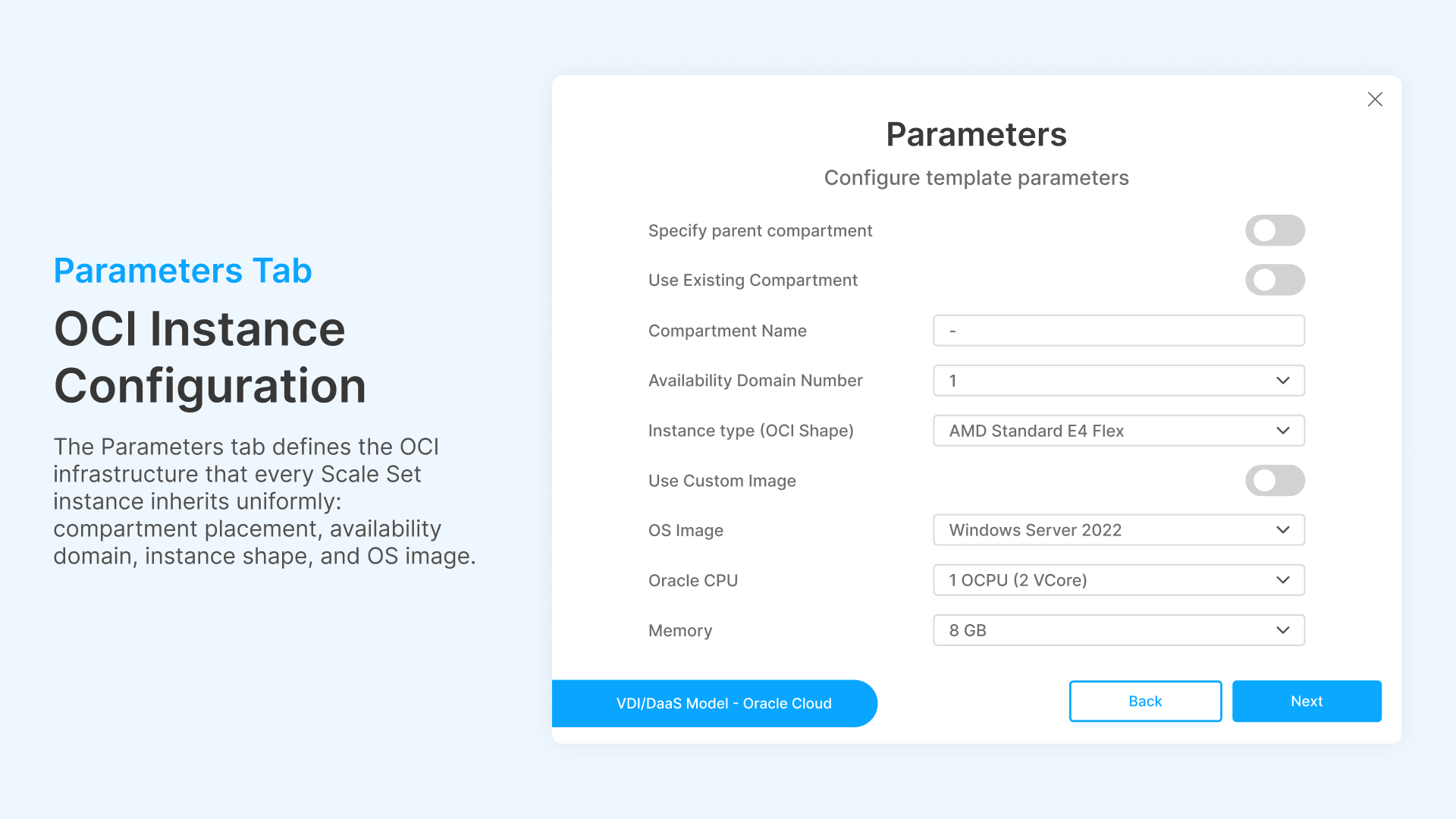
For an OCI deployment, the parameters include:
- Compartment: The OCI compartment where instances are provisioned. Cloud Manager supports specifying a parent compartment or using an existing compartment by OCID. This aligns with enterprise OCI tenancy structures where VDI workloads have their own compartment for billing isolation and IAM policies.
- Availability Domain: The OCI Availability Domain number (1, 2, or 3 depending on region). Distributing Scale Sets across ADs provides fault tolerance—if AD-1 experiences an outage, Scale Sets in AD-2 continue serving sessions.
- Instance Type: The compute shape. OCI’s AMD Standard E4 Flex shape provides configurable CPU and memory: you specify OCPUs (1 OCPU = 2 vCores) and memory independently. A typical VDI host might use 1 OCPU (2 vCores) and 8 GB memory for knowledge-worker sessions, or 4 OCPUs (8 vCores) and 32 GB for power users.
- OS Image: The golden image for provisioned instances. Windows Server 2022 is the standard for multi-session RDS hosts. Custom images with pre-installed applications can be specified for faster provisioning (no post-boot software installation needed).
- Disk Size: Boot volume size in GB. Default 60 GB for a Windows Server 2022 base image with standard applications. Larger disks for environments with local application caches or temporary file storage.
- Network Configuration: Assign Public IP (yes/no), DNS label, subnet placement. For production VDI, instances typically get private IPs with access through Thinfinity’s reverse proxy—no public IP exposure.
- Domain Join: Automatically join provisioned instances to an Active Directory domain. Essential for enterprise environments where GPO, Kerberos authentication, and NTLM fallback depend on domain membership. Cloud Manager includes a configurable wait timer (‘Wait for instance to be ready’) defaulting to 20 seconds to ensure the instance is fully booted and network-attached before attempting the domain join.
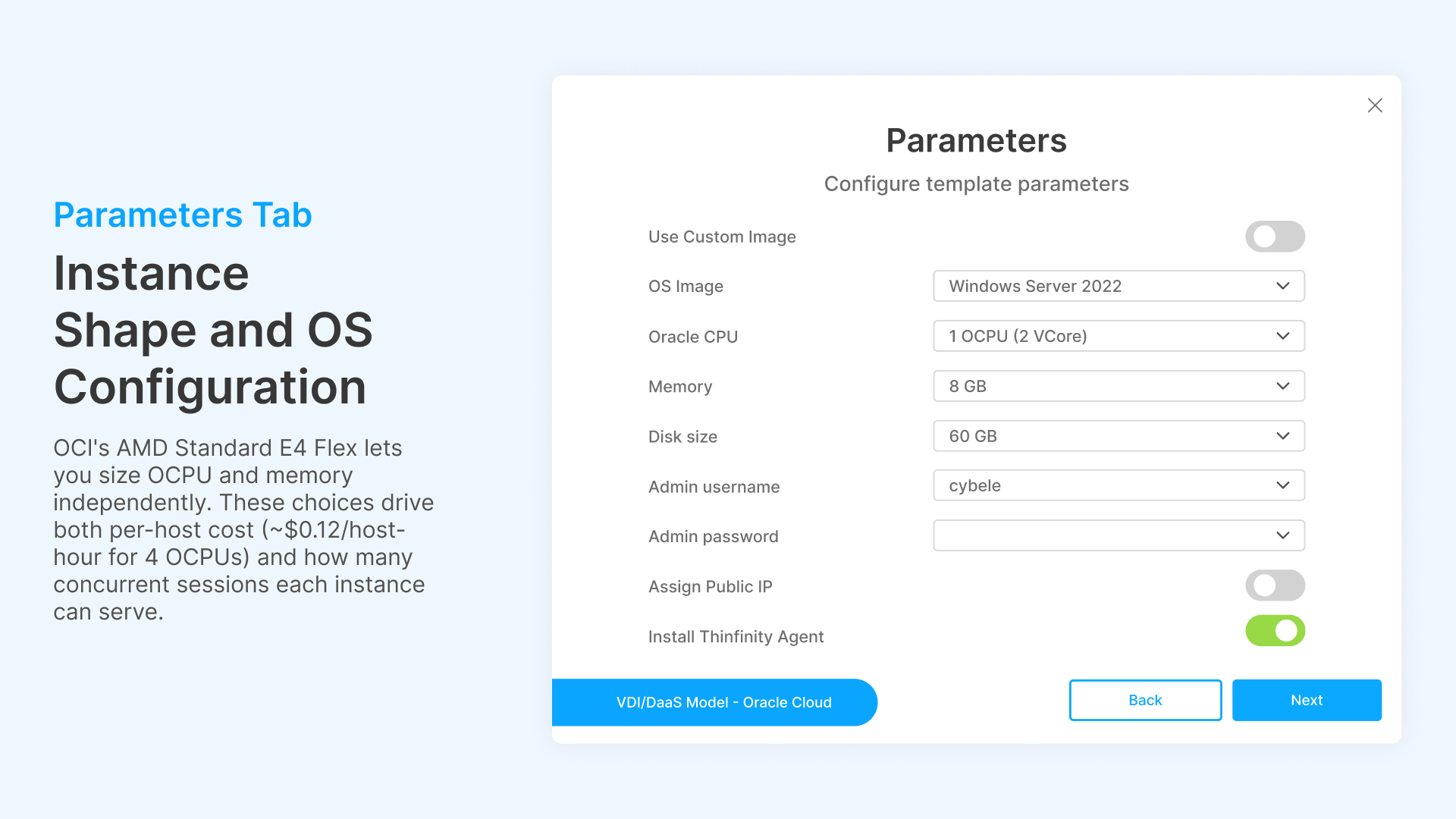
These parameters are identical for every instance in the Scale Set. When a Lazy Instance spins up at 8:45 AM, it’s provisioned with exactly this specification—same shape, same image, same network config, same domain join. Consistency is enforced by design, not by operator discipline.
Infrastructure as Code: Terraform Templates
Cloud Manager uses Terraform as its infrastructure-as-code engine. Every Scale Set’s infrastructure definition is stored as a set of Terraform files that you can inspect, modify, version-control, and audit. The Templates section in Cloud Manager exposes four files:
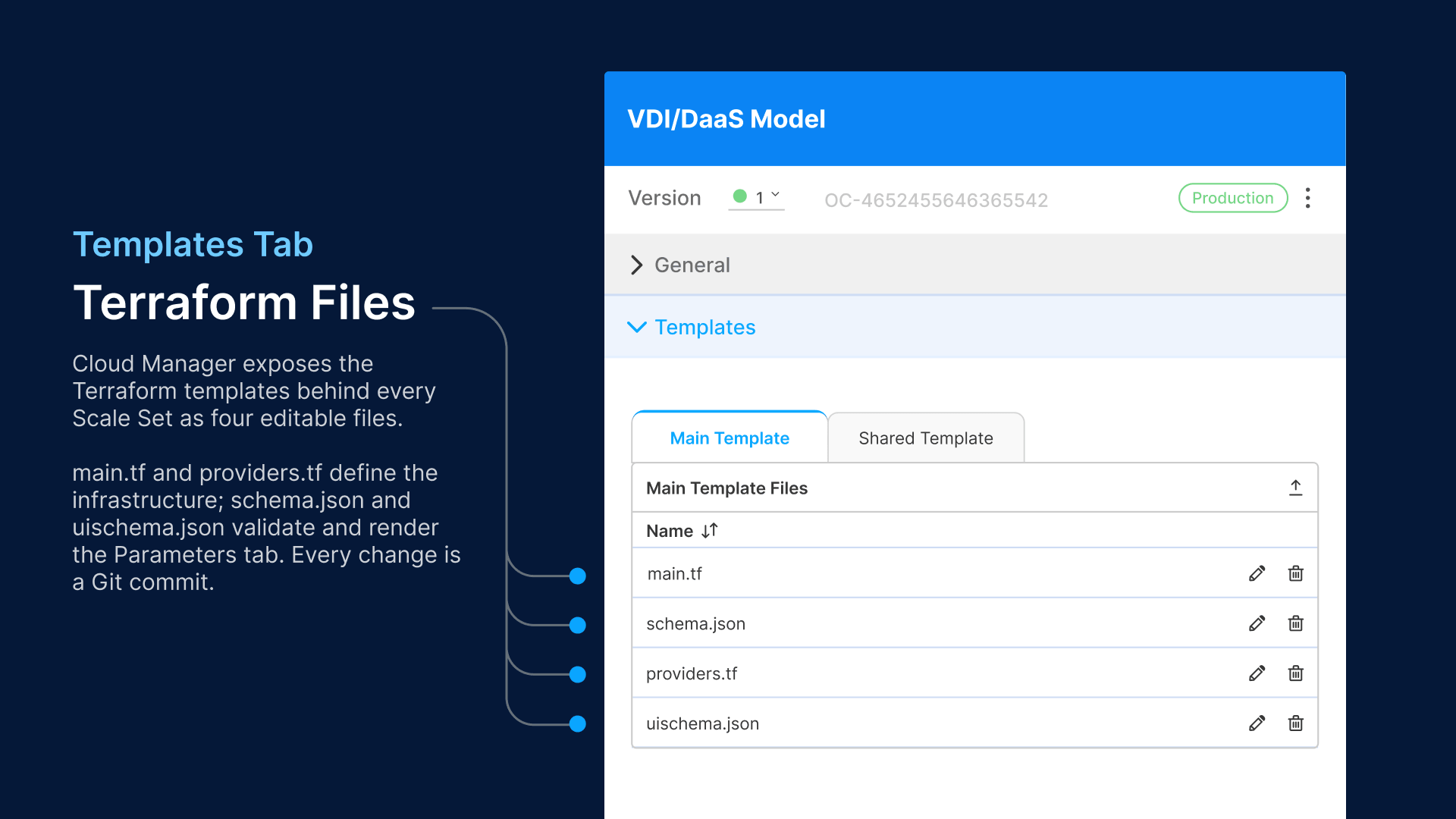
main.tf: The Infrastructure Definition
The main.tf file defines the OCI resources that Cloud Manager provisions for each instance. Key resources include:
- ociidentityavailability_domain: Data source that resolves the Availability Domain name from the domain number you specified in Parameters.
- ocicoreimages: Data source that filters available OS images by operating system (‘Windows’) and version (‘Server 2022’). This ensures the latest patched image is used if you haven’t specified a custom image OCID.
- ocicoreinstance: The instance resource itself. Defines the compute shape (VM.Standard.E4.Flex), shapeconfig (ocpus and memoryingbs), sourcedetails (image OCID and boot volume size), and createvnicdetails (subnet, public IP, DNS label).
A simplified example of the instance resource block:
resource "oci_core_instance" "vdi_host" {
availability_domain = data.oci_identity_availability_domain.ad.name
compartment_id = var.compartment_id
display_name = "${var.naming_prefix}-${count.index + var.start_index}"
shape = "VM.Standard.E4.Flex"
shape_config {
ocpus = var.ocpus # e.g., 1 (= 2 vCores)
memory_in_gbs = var.memory_gbs # e.g., 8
}
source_details {
source_type = "image"
source_id = data.oci_core_images.win2022.images[0].id
boot_volume_size_in_gbs = var.disk_size # e.g., 60
}
create_vnic_details {
subnet_id = var.subnet_id
assign_public_ip = var.assign_public_ip
hostname_label = "${var.naming_prefix}-${count.index}"
}
}
providers.tf: Cloud Provider Configuration
The providers.tf file declares the Terraform provider and version constraints. For OCI:
terraform {
required_providers {
oci = {
source = "oracle/oci"
version = ">= 6.35.0"
}
}
}
provider "oci" {
tenancy_ocid = var.tenancy_ocid
user_ocid = var.user_ocid
fingerprint = var.api_fingerprint
private_key_path = var.api_private_key_path
region = var.region
}
The provider version pin (>= 6.35.0) ensures compatibility with current OCI API features. For multi-cloud deployments, you’d have separate providers.tf files for AWS (hashicorp/aws), Azure (hashicorp/azurerm), or GCP (hashicorp/google)—each with its own credential configuration. Cloud Manager manages the provider selection based on the Scale Set’s target cloud.
schema.json and uischema.json: Parameter Validation
The schema.json file defines the JSON Schema for all configurable parameters—compartment OCID, domain join settings, instance shape, and credentials. The uischema.json controls how these parameters are rendered in Cloud Manager’s UI (field grouping, layout, ordering). These files ensure that every Scale Set configuration is validated against a known schema before Terraform apply runs—preventing misconfiguration from reaching the cloud provider’s API.
The practical value of Terraform-backed scaling is audit compliance. Every infrastructure change—every Scale Set creation, every parameter modification, every schedule adjustment—is a Git commit. SOX auditors reviewing your VDI infrastructure get a version-controlled history of every change, who made it, and when. No screenshots of GUI settings. No ‘we think the config was changed last Tuesday.’ The Git log is the audit trail.
Multi-Cloud Scaling: Same Logic, Any Provider
Thinfinity Cloud Manager’s auto-scaling engine is cloud-agnostic. The scaling logic—Scale Sets, deploy/destroy schedules, drain procedures, VDI deployment modes—is identical across OCI, AWS, Azure, GCP, and IONOS. You define the scaling policy once. Cloud Manager executes it against whichever cloud provider hosts that Scale Set.
This matters for three scenarios:
Scenario 1: Multi-Region, Single Cloud
A global enterprise running VDI on OCI across three regions (US Phoenix, EU Frankfurt, APAC Tokyo) defines three Scale Sets with region-appropriate schedules. US scales for 9 AM–7 PM ET. EU scales for 9 AM–7 PM CET. APAC scales for 9 AM–7 PM JST. Same scaling logic, different time windows. Cloud Manager handles the timezone offset automatically.
Scenario 2: Multi-Cloud Failover
Primary VDI runs on OCI (cost advantage with E4.Flex pricing). If OCI capacity in a region hits Max Instances, overflow connections route to AWS (configured as a secondary Scale Set). Users experience no interruption—the connection broker directs them to the next available host, regardless of which cloud it runs in. When OCI capacity frees up, new connections route back to the primary.
Scenario 3: Cloud Arbitrage
Different Scale Sets on different clouds, optimized for price. OCI E4.Flex for baseline (lowest per-core cost). AWS Spot Instances for overflow (up to 70% cheaper than on-demand). GCP Preemptible for non-critical dev/test VDI (up to 80% cheaper). Cloud Manager routes sessions to the most cost-effective available capacity.
None of this is possible with Citrix Autoscale (single control plane), Omnissa Horizon (vSphere-centric pool management), or Azure AVD (Azure-only). Multi-cloud VDI scaling requires a cloud-agnostic orchestration layer. That’s what Cloud Manager provides.
Credentials and Connection Modes
Each VDI/DaaS model in Cloud Manager is associated with a cloud credential set and a connection mode.
- Credentials: Cloud Manager stores cloud provider credentials (OCI API keys, AWS IAM access keys, Azure service principals) securely. Each Scale Set references a credential by name (e.g., ‘oci_cred’). This separates infrastructure secrets from scaling configuration—your Terraform templates reference credential names, not embedded keys.
- Connection Mode: Defines how users connect to provisioned instances. Options include Public IP (direct RDP to a public-facing instance—suitable for dev/test only), Private IP via Thinfinity Gateway (production-grade: instances have private IPs, users connect through Thinfinity’s HTML5 reverse proxy with zero client software), and VPN-tunneled connections for hybrid environments.
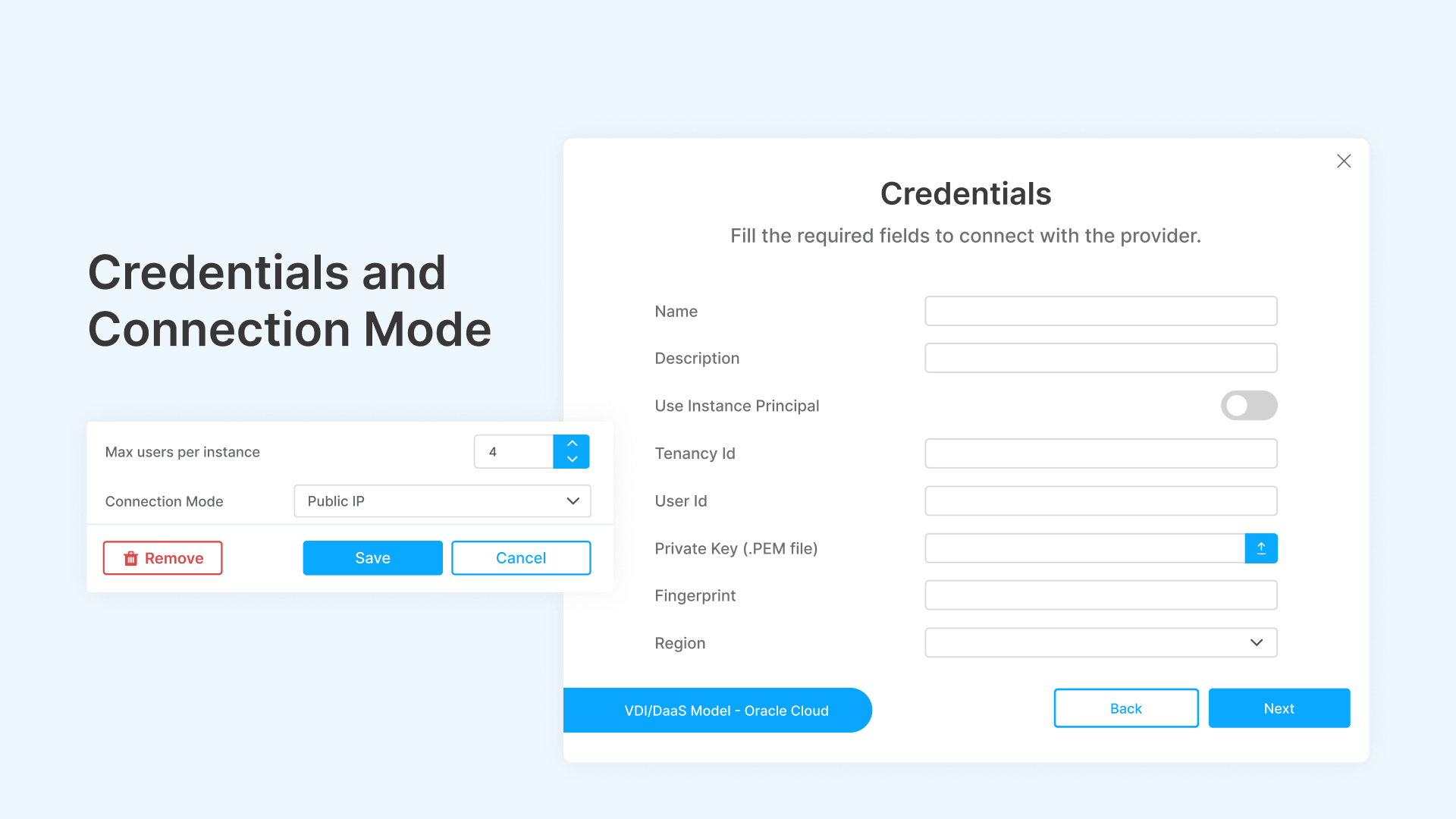
For production deployments, Private IP via Gateway is the standard. Instances never expose public IPs. All user traffic routes through Thinfinity’s gateway, which handles authentication (SAML, MFA), session encryption (TLS 1.3), and protocol optimization (adaptive bandwidth compression for high-latency links).
ROI Model: Always-On vs. Scheduled On/Off
Let’s model a realistic 1,000-seat deployment on OCI for a standard office-hours operation (9 AM–7 PM, Monday–Friday).
Assumptions
- Peak concurrency: 1,000 users during business hours.
- Sessions per host: 8 (session-based deployment, knowledge workers).
- Hosts at peak: 125 (1,000 ÷ 8).
- Initial Instances: 20 (always-on baseline, 16% of peak).
- OCI E4.Flex cost: $0.12/host-hour (4 OCPUs, 8 GB RAM).
- Scheduled window: Monday–Friday 9 AM–7 PM = 50 hours/week.
- Annual compute hours (always-on): 125 hosts × 8,760 hours = 1,095,000 host-hours.
- Annual compute hours (scheduled): 20 hosts × 8,760 + 105 hosts × 2,600 hours = 175,200 + 273,000 = 448,200 host-hours.
| Cost Category | Always-On (Legacy) | Scheduled On/Off (Thinfinity) |
|---|---|---|
| Compute (OCI E4.Flex) | $131,400/yr | $53,784/yr |
| Windows Server Licensing | $80,000/yr | $80,000/yr |
| Storage (50 TB persistent) | $24,000/yr | $24,000/yr |
| Network Egress | $12,000/yr | $12,000/yr |
| Thinfinity Licensing | — | $48,000/yr |
| Annual Total | $247,400 | $217,784 |
| 3-Year TCO | $742,200 | $653,352 |
| 3-Year Savings | — | $88,848 (12%) |
The 12% savings on a 1,000-seat deployment may seem modest, but this model uses conservative assumptions (only office hours, no weekend work, standard density). For shift-work operations (3 shifts, 24/7) or deployments with significant off-hours periods, the savings increase to 30–50%.
| Deployment Pattern | Annual Compute Savings | 3-Year TCO Savings |
|---|---|---|
| Office Hours Only (50 hrs/wk) | 59% compute reduction | $88,848 |
| 2-Shift Operation (80 hrs/wk) | 52% compute reduction | $144,000+ |
| Contact Center (variable demand) | 40–65% compute reduction | $200,000+ |
| Dedicated Desktops (on/off) | 70% per-VM compute reduction | $350,000+ |
At 5,000 seats, multiply the savings by 4–5×. At 10,000 seats across multiple clouds, the annual savings in compute alone reach $500,000–$1M before accounting for operational efficiencies (fewer hosts to patch, fewer licenses to track, reduced attack surface during off-hours).
Implementation: Configuring Auto-Scaling Step by Step
Step 1: Create the VDI/DaaS Model
Navigate to Cloud Manager > VDI/DaaS Models > Create New. Define the model name (e.g., ‘Call Center’), naming prefix (e.g., ‘CC-‘ with 3 digits starting at index 001), and set the state to Active. Select your cloud credentials (e.g., ‘oci_cred’) and connection mode.
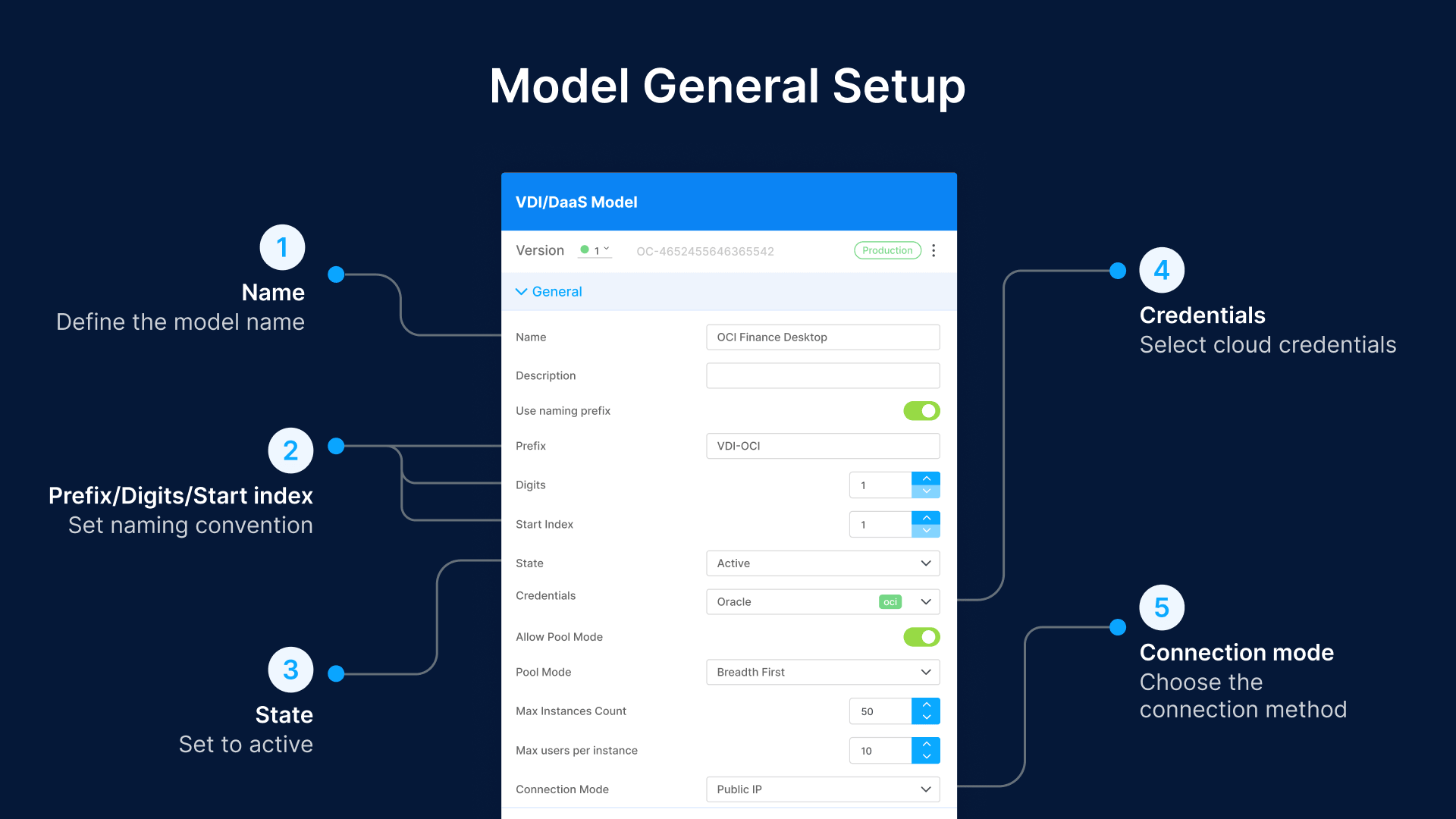
Enable Pool Mode for session-based deployments. Enable Dynamic Assignment to distribute sessions across hosts evenly. For dedicated deployments, disable both—each user gets a fixed VM assignment.
Step 2: Configure Scale Set Parameters
In the Scale Set’s Parameters tab, define the cloud infrastructure specification: compartment, availability domain, instance shape (AMD Standard E4 Flex), OS image (Windows Server 2022), CPU (1 OCPU / 2 vCores), memory (8 GB), disk (60 GB). Set domain join options if your environment requires Active Directory integration.
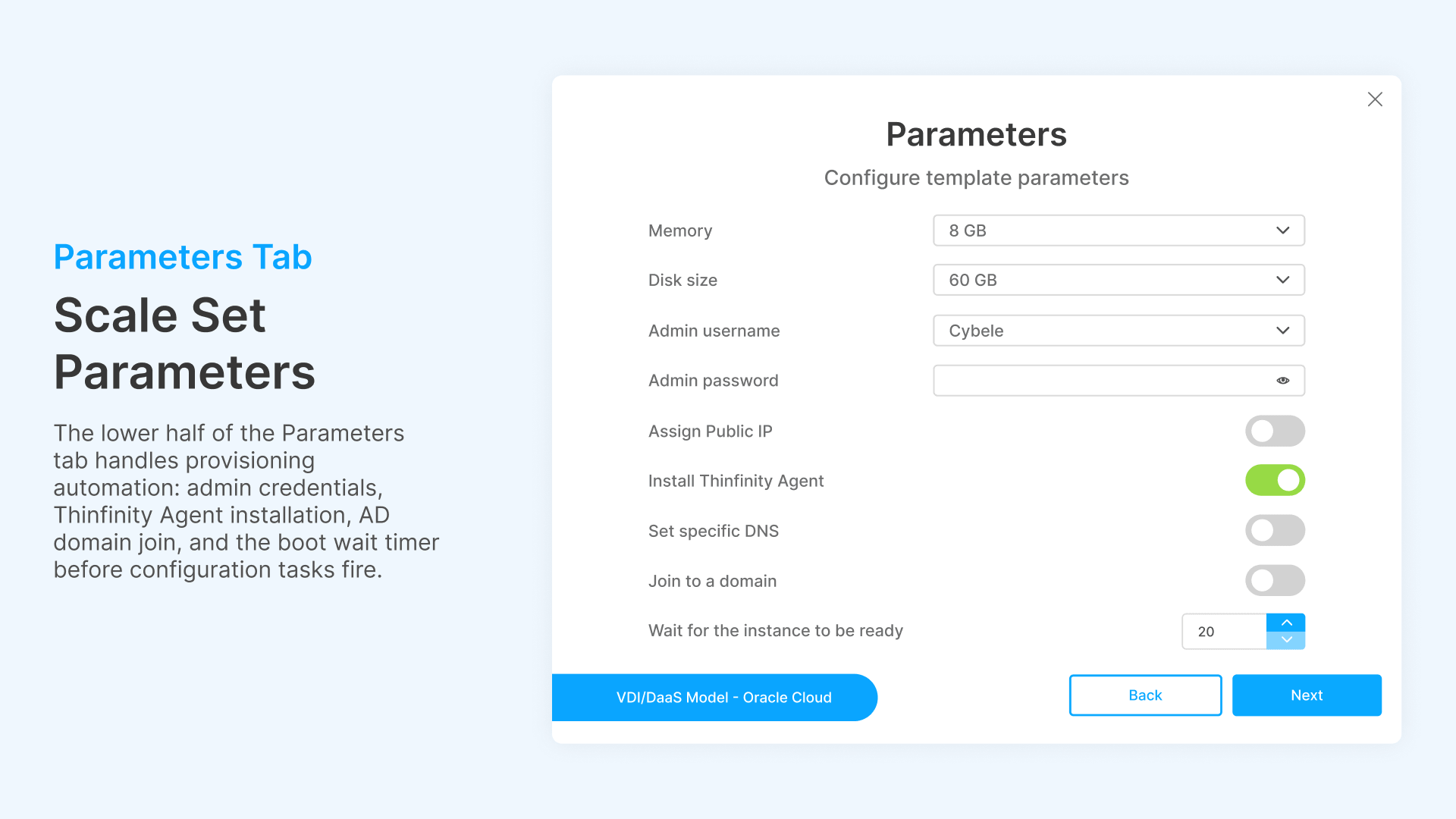
Step 3: Set Deploy and Destroy Modes
Choose your Deploy mode: Scheduled for predictable workloads, On Demand for variable workloads, or Both for the hybrid approach. If Scheduled, define the weekly grid—select active days and set the From/To time range for each day. Choose your Destroy mode: Scheduled for cost optimization (instances power off outside the schedule), or Never for persistent environments.
Step 4: Review Terraform Templates
Inspect the auto-generated Terraform files (main.tf, providers.tf, schema.json, uischema.json). Verify the instance resource configuration matches your requirements. If you need customizations—additional provisioner scripts, custom tags, specific networking rules—edit the templates directly. Cloud Manager applies your customizations on the next scaling event.
Step 5: Deploy and Monitor
Apply the Scale Set. Cloud Manager runs Terraform plan to preview the infrastructure, then Terraform apply to provision Initial Instances. Monitor the Scale Set dashboard for instance status, session count, and scaling events. Validate that scheduled scaling fires at the configured times by checking the first business day after deployment.
Continue reading: https://www.cybelesoft.com/manuals/cloud-manager-8.5/advanced/staged-power-on-off/configuring-staged-power-onoff
Bottom Line
Cloud VDI billing is per-hour. Your users don’t work 168 hours a week. Every hour a VM runs without serving a session is money leaving your cloud budget.
Thinfinity Cloud Manager’s auto-scaling engine closes that gap. Schedule-based on/off matches compute to business hours. Session-based scaling matches host count to actual demand. Dedicated desktop scheduling matches persistent VMs to user work patterns. Terraform-backed IaC makes every configuration change auditable, repeatable, and version-controlled.
The infrastructure you need, running only when you need it. Nothing more.